Jump to section
- How to Scrape Google Lens Products Step by Step
- Tools and Setup Requirements
- Data Extraction Process
- Tips for Reliable Data Collection
- How Web Scraping HQ Makes Google Lens Product Scraping Easier
- Platform Features for Product Data Extraction
- Advantages of Using Web Scraping HQ Services
- Business Uses for Google Lens Product Scraper Data
- Price Tracking and Market Analysis
- Product Catalog and Inventory Management
- Machine Learning Model Development
- Conclusion
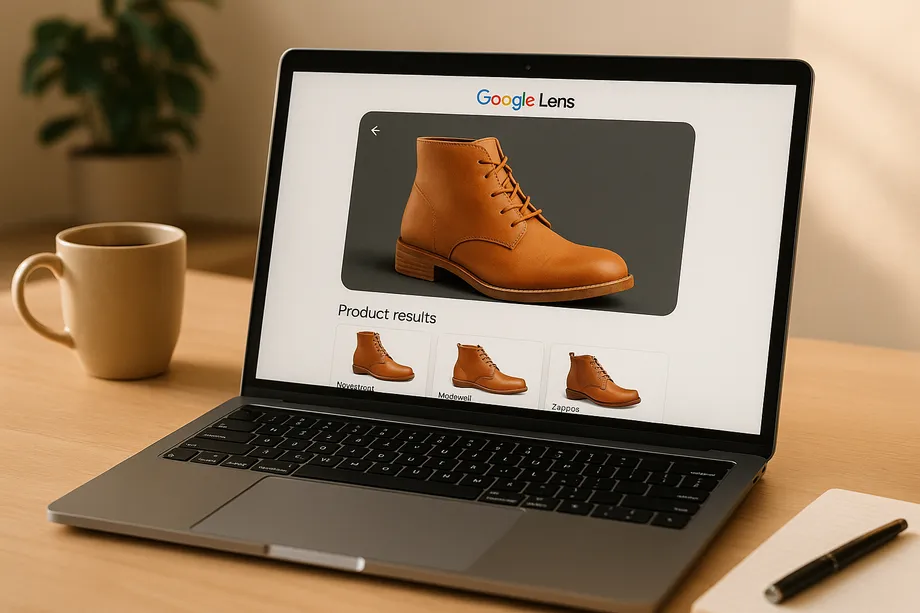
How to Scrape Google Lens Products?
Scraping Google Lens product data can provide businesses with valuable insights like pricing trends, competitor analysis, and inventory details. However, it’s not straightforward due to dynamic content, JavaScript rendering, and anti-scraping measures like CAPTCHAs. Developers often use tools like Selenium, Puppeteer, or APIs from providers such as Oxylabs and SerpApi to extract this data. Legal and ethical considerations, including compliance with Google’s Terms of Service and privacy laws like GDPR, are equally important.
Key takeaways:
- Challenges: JavaScript-heavy content, CAPTCHAs, rate limits, and IP blocking.
- Solutions: Tools like headless browsers (Selenium, Puppeteer), APIs (Oxylabs, Scrapingdog), and managed services (Web Scraping HQ).
- Ethical Scraping: Respect robots.txt, avoid overloading servers, and comply with legal guidelines.
- Applications: Price tracking, inventory management, and machine learning model training.
For those seeking a streamlined approach, managed services like Web Scraping HQ handle the technical and legal complexities, delivering structured, ready-to-use data for business needs.
How to Scrape Google Lens Products Step by Step
Creating a Google Lens product scraper takes careful planning and the right tools. A well-designed scraper doesn’t just collect data - it can also provide insights into pricing strategies and inventory trends. To get started, you’ll need to set up your environment, establish a workflow for data extraction, and optimize for consistent results. Let’s break it down step by step.
Tools and Setup Requirements
To handle Google Lens's dynamic structure, your scraper will need specific tools and libraries. Python is a popular choice for such tasks, thanks to its straightforward syntax and extensive library support.
A fundamental tool is the requests library, which facilitates HTTP communication with Google Lens APIs. You can install it using this command: pip install requests.
For API-based scraping, here’s how some key services work:
-
Scrapingdog's Google Lens API: You’ll need your API key and the image URL you want to analyze. Using the
requestslibrary, you can send GET requests and receive results in JSON format. - Oxylabs' Google Lens API: This requires a payload that includes the source ("google_lens"), your image URL, and the parse option set to "true." Authentication is managed with your Oxylabs username and password, and you’ll send POST requests to their API endpoint.
- Scrapeless Google Lens API: Configure the payload with the engine set to "google_lens", search type as "products", and your image URL. Include an API token in the headers and send a POST request to the endpoint.
For those who prefer direct scraping methods, tools like Selenium and Beautiful Soup are alternatives. Selenium is great for handling JavaScript-heavy pages, while Beautiful Soup simplifies HTML parsing. However, these methods often require more setup and maintenance.
Another option is ZenRows, which simplifies scraping by managing proxy rotation and anti-detection measures for you.
Data Extraction Process
Once your tools are ready, the next step is to execute your queries and process the results efficiently. The workflow typically involves preparing your image input, running the query, and handling the output.
For example, SerpApi demonstrated in January 2023 how it could extract reverse image search links, knowledge graph details (like titles, thumbnails, and visual matches), and more from image URLs. Their system bypasses blocks and CAPTCHAs automatically, delivering results in under 4.3 seconds per request - no browser automation required.
Here’s how the process unfolds:
- Prepare the image input: Whether your images are stored locally or hosted online, your scraper must format them correctly. Most APIs accept direct URLs, but some may require base64 encoding or file uploads.
- Configure the query: Set parameters like search type (e.g., products, text, objects), result limits, and output preferences. Be sure to include error handling for issues like timeouts or invalid formats.
- Process the response: Extract useful data from the API's JSON response. Google Lens results often include product names, prices, merchant details, and availability. Convert this data into formats like CSV or database entries for easier analysis.
- Validate the data: Check for missing or incomplete details, ensure price formats are correct, and filter out irrelevant results to maintain accuracy.
Tips for Reliable Data Collection
To ensure your scraper runs smoothly and avoids detection, follow these best practices:
- Pace your requests: Add random delays between requests to mimic natural browsing behavior and reduce the risk of being blocked.
- Rotate user agents: Use different user agents and proxies to stay anonymous and avoid IP bans.
- Handle errors gracefully: Implement error handling for timeouts, rate limits, and invalid inputs. Log errors for troubleshooting and set up automatic retries for temporary failures.
- Monitor performance: Track metrics like response times and success rates. Set up alerts for unusual patterns, which could indicate detection or API changes.
- Normalize your data: Clean and standardize product names and prices to remove inconsistencies and duplicates.
- Manage pagination: Some queries may span multiple result pages. Ensure your scraper can navigate through them systematically to collect all relevant data.
- Test regularly: Run automated tests to catch changes in Google Lens's structure. These tests should verify key fields and notify you of any missing elements.
How Web Scraping HQ Makes Google Lens Product Scraping Easier
Building a Google Lens product scraper from scratch comes with its fair share of hurdles. From managing dynamic content to ensuring compliance, the technical challenges can be overwhelming. But Web Scraping HQ simplifies this process with a managed solution that handles everything behind the scenes. Instead of spending time on infrastructure and coding, you can focus on using the data to make smarter business decisions.
With Web Scraping HQ, you don’t have to worry about technical roadblocks like proxy rotation, anti-detection strategies, or Google Lens’s frequent updates. The platform takes care of these complexities, ensuring your scraper runs smoothly while you concentrate on scaling your business.
Platform Features for Product Data Extraction
Web Scraping HQ’s tools are designed to manage all the technical intricacies of extracting data from Google Lens. The platform provides a ready-to-use Google Lens product scraper that automatically adjusts to Google’s updates, ensuring uninterrupted data collection even when interface or security changes occur.
The platform also offers custom data formatting, delivering product data exactly how you need it. Whether it’s pricing data in specific currencies, product descriptions cleaned of unnecessary HTML, or inventory details sorted by region, the platform provides structured, ready-to-use data. This saves you the hassle of cleaning and normalizing raw data before applying it to your business.
Legal compliance is another area where Web Scraping HQ shines. Web scraping legality depends on factors like the type of data collected, how it’s used, and the methods employed. The platform ensures your scraper operates within legal boundaries by adhering to best practices, keeping up with regulatory changes, and managing technical elements like server operations and proxy rotations automatically.
To guarantee data reliability, Web Scraping HQ integrates quality assurance checks. These automated validation mechanisms catch issues like missing product details, incorrect price formats, or duplicate entries. This means the data you receive is accurate and ready to use, saving time on manual reviews and ensuring seamless integration into your business processes.
Advantages of Using Web Scraping HQ Services
One of the biggest benefits of using Web Scraping HQ is the time saved on development. Instead of spending months building and testing a custom scraper, you can have your data extraction running in just a few days. This speed gives businesses the agility to respond quickly to market changes and competitive pressures.
The platform also provides clean, structured data in formats that easily integrate with your existing systems. Whether you need JSON for APIs, CSV for spreadsheets, or direct database connections, the platform offers flexible output options. This eliminates the need for additional processing, freeing up valuable resources.
For e-commerce businesses, the platform offers industry-specific solutions tailored to common needs like tracking competitors’ prices, monitoring inventory levels, and identifying new product launches. These features are designed with retail operations in mind, making it easier to stay ahead in a competitive market.
Web Scraping HQ’s pricing reflects the convenience of managed services. The Standard plan, priced at $449/month, includes structured data delivery, automated quality checks, and compliance support within a 5-day timeframe. For businesses needing faster service or custom data formats, the Custom plan starts at $999/month and offers enterprise-level features, including 24-hour delivery and priority support.
Ethical scraping is a core principle of Web Scraping HQ. The platform respects industry standards by implementing rate limits, honoring robots.txt files, and avoiding overly aggressive data collection that could disrupt target websites. This responsible approach not only ensures reliable data access but also reduces the risk of legal complications, enabling businesses to confidently use the data for market analysis, inventory management, and other strategic purposes.
sbb-itb-65bdb53
Business Uses for Google Lens Product Scraper Data
Using data extracted via a Google Lens product scraper opens up a range of opportunities for businesses. This visually rich product data empowers companies to make informed decisions, refine strategies, and improve processes. Unlike traditional text-based tools, Google Lens data offers deeper insights that can be applied to pricing, inventory management, and even advanced AI model training. For businesses operating in product-driven markets, this data becomes a critical resource for staying ahead.
Price Tracking and Market Analysis
One of the most impactful uses of Google Lens product scraper data is in pricing strategy and market analysis. In today’s highly competitive retail environment, pricing plays a pivotal role - 83% of online shoppers compare prices across multiple websites before making a purchase. A Google Lens product scraper allows businesses to monitor competitor pricing in real time, helping them adapt quickly. In fact, 82% of retailers now rely on dynamic pricing strategies to remain competitive.
Take Tradeinn, for example. This retailer tracks prices for 10 million products daily, drawing data from 50,000 sellers listed on Google Shopping. Such comprehensive data collection enables businesses to uncover pricing trends and identify new market opportunities. One niche retailer, for instance, used this data to increase profit margins on 14% of its products while improving competitiveness on 95% of its offerings. Another electronics retailer leveraged this pricing insight during a major sales event, detecting competitors’ special offers and responding with even better deals. By analyzing pricing patterns over time, businesses can anticipate seasonal trends, fine-tune their strategies, and maximize both competitiveness and profitability.
Product Catalog and Inventory Management
Google Lens product data also plays a major role in inventory management. By capturing visual details like packaging, product conditions, and design features, the scraper helps businesses maintain accurate and up-to-date product catalogs. This automated approach reduces manual errors and ensures product descriptions remain consistent across sales platforms.
For retailers, this consistency is crucial. A Google Lens product scraper can verify that product images and details are uniform across websites, improving the overall shopping experience and boosting customer trust. Additionally, timely updates to inventory records enhance operational efficiency, making it easier for businesses to manage stock levels and meet customer expectations.
Machine Learning Model Development
The data collected through Google Lens isn’t just useful for operations - it’s also a goldmine for machine learning applications. The combination of visual and textual data is perfect for training e-commerce AI models. These models can power advanced tools like product recognition systems, automated categorization, and personalized recommendation engines. By analyzing attributes, customer reviews, and ratings, businesses can create systems that offer highly targeted product suggestions.
This approach doesn’t just improve sales - it also enhances the customer experience. Personalized recommendations ensure shoppers see products that match their preferences, leading to higher satisfaction and conversion rates. AI is already making waves in e-commerce, with 64% of SaaS professionals believing it improves customer relations and productivity. Over half (55%) of companies are already using AI for personalized services, and Gartner predicts that by the end of 2024, more than 60% of businesses will rely on AI as a core tool. The need for high-quality training data, like that provided by a Google Lens product scraper, is only growing.
Conclusion
A dependable Google Lens product scraper can transform how businesses access and utilize visual product data. With the ability to extract detailed product information, pricing, and market trends directly from Google Lens, companies gain a clear edge in competitive industries. Whether it's real-time price tracking or leveraging data for machine learning, these insights are crucial for informed decision-making and strategic planning.
In today’s data-driven world, a reliable Google Lens product scraper is more than a tool - it’s a strategic asset. Solutions like those from Web Scraping HQ not only streamline the process but also equip businesses to lead in increasingly competitive markets.
Want this done for you?
Send us the URLs. We'll quote it in 24 hours.
Paste the URL(s) you want scraped. We'll reply within 24 hours with a feasibility check and a ballpark quote.


