Jump to section
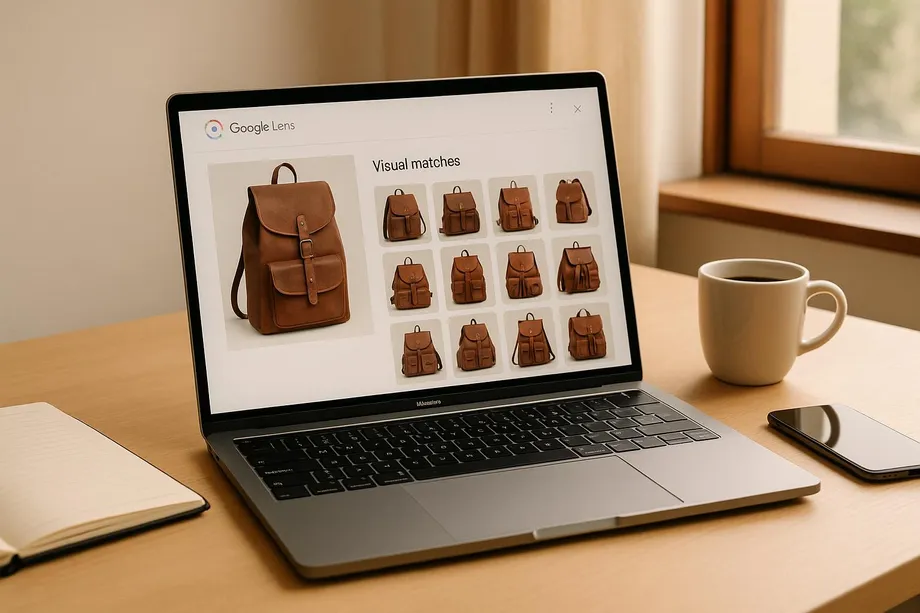
How to Scrape Google Lens Visual Matches?
Scraping Google Lens visual matches can help businesses analyze similar products, pricing trends, and market shifts. However, it comes with technical and legal challenges.
Managed services like Web Scraping HQ can streamline the process, offering monthly plans starting at $449. They handle infrastructure, proxies, and compliance, making it easier to extract and use visual match data effectively.
How to Scrape Google Lens Visual Matches
Once you've set up the technical groundwork and ensured compliance with legal guidelines, you're ready to begin scraping Google Lens visual matches. Here's how to proceed step by step.
Getting API Access and Preparing Image URLs
To start, you'll need proper API access and a collection of image URLs ready for processing. Several APIs are designed to simplify this task. For instance, Webscraping HQ provides a dedicated Google Lens API that lets you specify the result type using the "type" parameter. By setting this to "visual_matches", you can directly target the visual matches tab.
Your image URLs must be publicly accessible and formatted correctly (e.g., JPG, PNG, or WebP). Hosting these images on fast, reliable servers is critical to avoid timeout errors during scraping. Additionally, Webscraping HQ offers an API that extracts fields like title, URL, and position from visual match results.
For the best results, use high-resolution images with clear and unedited subjects. Overly filtered or heavily altered images can confuse Google Lens' matching algorithms, reducing accuracy. By following these steps, you'll be well-prepared to scrape visual matches effectively.
Configuring Your Scraper
Next, you’ll need to configure your scraper for optimal performance. If you're building a custom scraper using Python, tools like Selenium or Puppeteer are indispensable for handling JavaScript-rendered content. For API-based solutions, configure your requests with the appropriate parameters. For example, with SerpApi, you can use the "search_type" parameter to refine your results and add localization options using parameters like "hl" (language) and "country".
To avoid detection, incorporate rotating user agents and proxies. Additionally, include robust error-handling mechanisms - such as retry logic, timeout management, and data validation - to keep your scraper running smoothly.
Getting the configuration right is essential to ensure accurate data collection while avoiding common challenges like IP bans or incomplete results.
Running the Scraper and Collecting Data
Before diving into large-scale scraping, run a small test batch to validate your scraper's performance. This approach helps you spot issues early, saving API credits and reducing the risk of IP blocks.
Actowiz Solutions provides a versatile Google Lens API that can identify text, classify image types, and locate similar visuals via image URLs. To monitor your scraper, enable logging and implement exponential backoff for handling network timeouts and rate limits.
Organize your collected data from the outset. Save extracted information in formats like JSON or CSV to simplify future analysis. Key fields to track include image URLs, titles, source websites, similarity scores, and metadata (e.g., dimensions and file sizes). For larger datasets, batch processing - grouping multiple images into a single API call - can reduce request volume and improve efficiency.
To handle common issues like network failures or invalid URLs, integrate automatic retries with exponential backoff. Managed services like Web Scraping HQ can take care of proxy rotation, error recovery, and data formatting for you. This eliminates the need for complex infrastructure while ensuring consistent data quality and adaptability to platform updates.
Finally, store your data securely and implement backup procedures to safeguard the valuable information you've gathered. By combining these practices with tools like Web Scraping HQ, you can streamline your workflow and focus on leveraging the insights from your data.
Web Scraping HQ Managed Services
Need to extract Google Lens Visual Matches at scale without dealing with the technical headaches? Web Scraping HQ has you covered with their managed extraction services. This platform takes care of the heavy lifting - handling infrastructure, ensuring legal compliance, and delivering the data you need - so you can focus on what really matters: analyzing the insights. Below, we break down their service plans and how they make visual data collection seamless.
Service Plans and Features
Web Scraping HQ provides two tailored plans for businesses that frequently scrape Google Lens Visual Matches.
The Standard Plan, priced at $449 per month, delivers structured, ready-to-use data. It includes automated quality checks, expert consultations, and outputs in JSON or CSV formats, making it simple to integrate visual match data into your workflows.
For larger enterprises with complex needs, the Custom Plan starts at $999+ per month. This plan offers fully tailored data solutions, scalable infrastructure, and flexible output formats. Both plans prioritize ongoing legal compliance, ensuring your data scraping aligns with platform guidelines and terms of service.
Business Applications
Web Scraping HQ's managed services are used across industries to extract Google Lens Visual Matches for a variety of strategic goals.
- Product Research: Teams use visual match data to identify trending items, analyze competitor catalogs, and uncover new market opportunities. By finding similar products across platforms, businesses can stay ahead of the curve.
- Brand Monitoring: Companies track how their products appear in visual search results, gaining insights into brand visibility and positioning within the visual search ecosystem.
- Competitor Analysis: Marketing teams leverage this data to understand product associations, identify gaps in their offerings, and monitor emerging trends in their industry.
What sets Web Scraping HQ apart is their commitment to compliance. Their approach ensures that legal and ethical considerations are woven into every step of the process. Dedicated teams across legal, engineering, product, and data functions work together to maintain responsible scraping practices that respect platform guidelines and accountability. This robust framework not only simplifies data collection but also helps businesses navigate the challenges of scraping with confidence.
sbb-itb-65bdb53
Conclusion
Extracting data from Google Lens Visual Matches is no small task. It demands a mix of technical know-how, a strong grasp of legal requirements, and a focus on maintaining data quality. From configuring APIs to managing rate limits and validating data, every step requires precision to ensure reliable outcomes. That’s why many turn to managed services for a smoother experience.
We deliver your data in structured formats like JSON or CSV, paired with automated quality checks and expert support. This ensures your projects meet high standards for accuracy and compliance.
Whether you go for our Standard plan at $449 per month or opt for custom solutions starting at $999 monthly, Web Scraping HQ is committed to making your Google Lens Visual Matches scraping projects efficient and reliable. With enterprise-level support, you can focus on turning data into actionable insights while leaving the technical details to us.
Want this done for you?
Send us the URLs. We'll quote it in 24 hours.
Paste the URL(s) you want scraped. We'll reply within 24 hours with a feasibility check and a ballpark quote.


