Jump to section
- Key Steps:
- Compliance Note:
- Zoopla Property Data Structure
- Key Data Points in Zoopla Listings
- How Data Structure Affects Scraping
- Tools and Requirements for Scraping Zoopla
- Technical Skills and Tools Required
- Setting Up a Scraping Environment
- Step-by-Step Guide to Scrape Zoopla Property Listings
- Define Your Data Requirements
- Write and Test Your Scraper
- Handle Pagination and Dynamic Content
- Legal and Compliance Considerations
- Managed Zoopla Scraping with Web Scraping HQ
- Features and Benefits of Web Scraping HQ
- Conclusion
How to Scrape Zoopla Property Listings?
Scraping Zoopla property listings can provide detailed data on the UK housing market, including prices, locations, features, and agent information. This data is useful for market research, price analysis, and developing tools like AI-driven property assistants. However, Zoopla prohibits text and data mining in its Terms of Use, so any scraping must comply with legal guidelines.
Key Steps:
- Understand Zoopla's Data Structure: Listings include addresses, prices, features, agent details, and metadata. Data is structured in predictable HTML formats but may require handling JavaScript-rendered content.
-
Use the Right Tools: Python libraries like
requests, BeautifulSoup, and Selenium help extract and parse data. Proxies and managed APIs can bypass IP blocks and CAPTCHAs. - Handle Pagination and Dynamic Content: Navigate multi-page results and load JavaScript-based elements using tools like Selenium or Playwright.
- Plan and Test: Define specific data needs, test scrapers on sample pages, and implement error handling for missing data or HTML changes.
Compliance Note:
Scraping Zoopla without permission can breach their terms. Managed services like Web Scraping HQ offer compliant solutions, starting at $449/month, to deliver structured property data without legal risks.
Summary: Scraping Zoopla requires technical skills, careful planning, and legal compliance. Managed services simplify the process while ensuring adherence to Zoopla's terms.
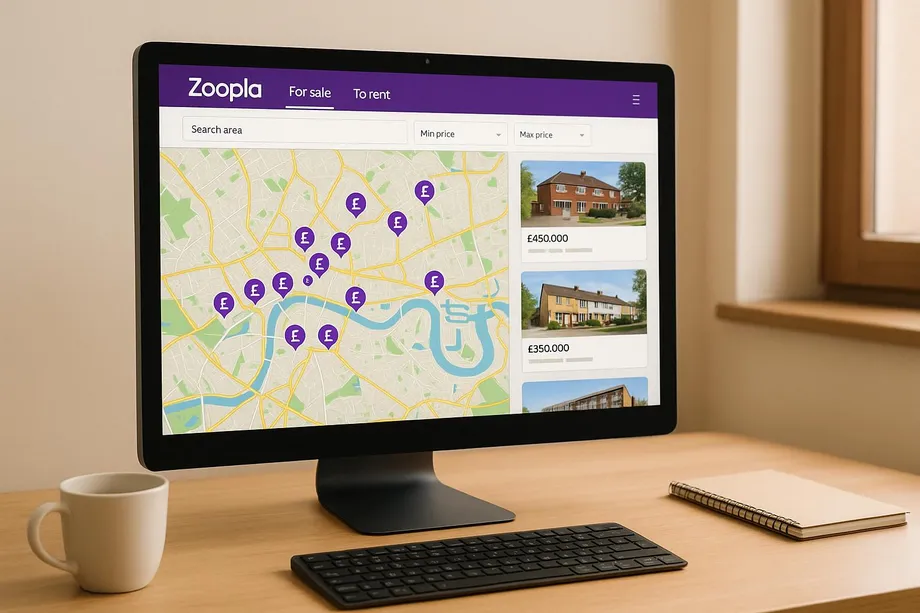
Zoopla Property Data Structure
To effectively scrape Zoopla, it's important to understand how the platform organizes its property data. Zoopla's listings follow a consistent structure across millions of properties, which simplifies the process of targeting specific data points. This predictable format is the backbone for creating reliable scraping tools and sets the stage for the technical steps we’ll discuss later.
Key Data Points in Zoopla Listings
Zoopla property listings are rich in structured information, offering a wealth of data that can be extracted. Here's a breakdown of the most commonly found data fields:
- Address Details: Each listing includes a detailed address, typically broken into street name, neighborhood, city, and postal code. This structure makes it easy to pinpoint locations and conduct geographic analyses.
- Pricing Information: For properties on sale, the asking price is displayed in British pounds. Rental listings show rates on a monthly or weekly basis. Many listings also feature historical pricing data, which tracks past asking prices and changes over time - valuable for analyzing market trends and investment opportunities.
- Physical Property Features: Listings usually include key details like the number of bedrooms and bathrooms, as well as property types (e.g., detached house, semi-detached, terraced house, flat, or bungalow). Additional features such as square footage, garden availability, and parking options are often part of the property description.
- Agent and Contact Information: Each listing typically provides the estate agent’s name, office address, and phone number, with some even offering individual agent details. This information is crucial for direct communication and for compiling agent directories.
- Listing Metadata: Metadata offers insights into market activity. For example, publication dates indicate when a property was listed, while view counts and inquiry numbers hint at buyer interest. Some listings also include the number of days the property has been on the market, helping gauge pricing strategy and desirability.
- Property Descriptions and Features: Text-based descriptions often highlight amenities, recent renovations, proximity to schools or transit, and neighborhood characteristics. Additional details like energy efficiency ratings, council tax bands, and leasehold information may also be included.
How Data Structure Affects Scraping
Zoopla's HTML layout plays a key role in how efficiently you can extract data. Property details are embedded in specific CSS classes and div containers that remain consistent across listings, making it easier to write and maintain your scraper.
- Price Data: Pricing information is typically located in containers tagged with classes like "price" or "listing-price." These sections usually include both the number and the currency symbol, so parsing is necessary to extract clean numerical data.
- Property Details: Features such as bedroom and bathroom counts, as well as property type, are often presented in predictable HTML lists. This regularity allows for straightforward targeting using CSS selectors or XPath expressions.
- Agent Information: Contact details for agents are often located in dedicated panels or footer sections, which follow a consistent HTML structure across listings. This consistency simplifies data extraction for building agent databases.
- Dynamic Content: Some elements, like images, contact forms, and virtual tours, load asynchronously via JavaScript. Scraping these requires tools capable of handling JavaScript-rendered content, as the data is not immediately available in the initial HTML.
- Pagination: Search results are organized into pages with clear next/previous buttons or numbered links. This predictable structure makes it easier to extract data in bulk, which is essential for large-scale scraping efforts.
- Search Results Layout: Listings on search result pages are typically displayed in grid or list formats, with each property enclosed in its own container. These containers summarize key details like price, location, and features, and link to detailed property pages for further data extraction.
Lastly, it's important to keep your scraper up to date with Zoopla’s layout changes. Websites frequently modify their structure, and staying vigilant will ensure your scraping tools remain effective. In the next section, we’ll dive into the tools and technical requirements needed to successfully scrape Zoopla listings.
Tools and Requirements for Scraping Zoopla
Scraping property listings from Zoopla requires a mix of technical skills and the right tools. To successfully extract data, you'll need to navigate dynamic content, handle challenges like IP blocking and CAPTCHAs, and set up a well-configured environment. Here's what you'll need to get started.
Technical Skills and Tools Required
Scraping Zoopla hinges on programming expertise, with Python being a top choice thanks to its robust web scraping libraries. For those with a background in web development, JavaScript with Node.js is another solid option.
-
HTTP client libraries: These tools manage communication with Zoopla's servers. Python's
requestslibrary is a go-to for basic HTTP requests, whilehttpxoffers asynchronous capabilities for faster operations. On the Node.js side,Axiosprovides similar functionality with a syntax tailored for JavaScript. -
HTML parsing tools: Extracting data from HTML is critical. Python's BeautifulSoup is a popular choice for parsing HTML using CSS selectors, while
parseladds XPath support for more complex needs. For Node.js,Cheeriomimics jQuery for server-side HTML manipulation. -
JSON processing: Many property details on Zoopla are embedded in JavaScript objects. Python's
jmespathlibrary is particularly useful for extracting and refining JSON data. - Handling dynamic content: Zoopla relies on JavaScript to load property details, so traditional scraping methods might not suffice. Tools like Selenium or Playwright can render JavaScript and retrieve fully loaded pages.
- Proxy management: To avoid IP blocking and CAPTCHAs, you’ll need proxies to rotate IP addresses. Managed scraping APIs like ScrapFly, Scrapingdog, or ScraperAPI simplify this process by combining proxy rotation with JavaScript rendering.
-
Data storage tools: After scraping, you’ll need to organize your data. Python's
pandaslibrary is excellent for structuring and exporting data to CSV files, whileOpenpyxlis ideal for creating Excel spreadsheets.
Setting Up a Scraping Environment
Once you've gathered the necessary tools, it’s time to configure your environment for efficient scraping. Start by downloading the latest version of Python, which includes pip for managing libraries.
-
Installing libraries: Use pip to install core dependencies like
requests, BeautifulSoup withlxmlfor faster parsing, andpandasfor data organization. - JavaScript rendering setup: For handling Zoopla's dynamic content, install Selenium along with browser drivers like ChromeDriver or GeckoDriver. Alternatively, Playwright offers a modern solution with built-in browser management, eliminating the need for manual driver setup.
- Proxy configuration: Depending on your approach, configure proxies to avoid detection. Premium proxy services usually provide API endpoints or credentials that integrate seamlessly into your requests. Managed APIs can handle proxy rotation and geographic targeting automatically.
-
Optimizing your development environment: Use virtual environments like
venvorcondato isolate dependencies and prevent conflicts. Configure your IDE with syntax highlighting and debugging tools to streamline development. Jupyter notebooks can be a great option for exploratory scraping and data analysis. - Testing and debugging: Browser developer tools are invaluable for inspecting HTML structure and network requests. Tools like Postman can help you test and refine HTTP requests, while logging can track performance and identify blocking issues early on.
The complexity of your setup will depend on your goals. If you're extracting basic property data, simple tools like HTTP requests and HTML parsers may be enough. For more comprehensive tasks, such as market analysis, you'll need advanced solutions like proxy management and dynamic content handling.
Step-by-Step Guide to Scrape Zoopla Property Listings
If you're planning to scrape property listings from Zoopla, it's important to approach the task methodically. This involves careful planning, writing code, and thorough testing to ensure accurate data extraction while respecting the platform's structure.
Define Your Data Requirements
Before diving into coding, take a moment to clarify what information you need. Zoopla offers a wide variety of property details, but narrowing your focus will make your scraper more efficient and easier to manage.
Start by identifying the key property attributes relevant to your project. For example, if you're analyzing the market, you might want to include details like energy ratings, council tax bands, or nearby amenities. By honing in on what matters most, you can avoid gathering unnecessary data.
Geographic focus is another critical aspect. Zoopla organizes properties by postal codes, cities, and regions. Whether you're targeting a specific area like "SW1A London" or a broader region such as "Greater Manchester", defining your geographic scope will save time and reduce irrelevant results.
Additionally, consider setting price ranges and filters to match your needs. Zoopla allows you to filter by price, property type (e.g., houses, apartments, new builds), and listing status (e.g., for sale, sold, rental). These parameters will help you construct more precise URLs and streamline your data collection process.
Once you've defined your requirements, you're ready to build and test your scraper.
Write and Test Your Scraper
The first step in coding your scraper is understanding Zoopla's HTML structure. Use your browser's developer tools to inspect the page and locate the elements containing the data you want.
Zoopla's property listings typically follow consistent patterns. For instance, price details may appear in elements with class names like "listing-results-price", while addresses are often found in "listing-results-address" containers. Other property details, such as the number of bedrooms or bathrooms, might be located in separate <span> or <div> elements.
Start with a basic Python script using libraries like requests and BeautifulSoup. Begin by fetching a single search results page and parsing its HTML to extract simple details like prices and addresses. Test your code on multiple listings to ensure your selectors work consistently across different property types.
As you collect data, decide how to store it effectively. Use Python dictionaries or pandas DataFrames to organize your extracted information. This structure makes it easy to export your data to CSV or JSON formats. Be sure to create columns for each data field and handle missing values gracefully, as some listings may lack specific details.
For more detailed information, you'll need to extract and visit individual property URLs from the search results. This two-step process allows you to gather additional data like full descriptions, floor plans, and photo galleries.
Handle Pagination and Dynamic Content
Once your scraper works for a single page, you’ll need to expand its functionality to handle multiple pages of search results.
Zoopla typically displays 25 properties per page, with navigation links at the bottom. To scrape all listings, your scraper must identify and follow these pagination links. Look for "Next" buttons or page number links in the HTML structure, extract the URLs, and apply your scraping logic to each page.
Dynamic content loading presents another challenge. Zoopla uses JavaScript to load certain elements like images, maps, and additional property details. Traditional HTTP requests won’t capture this content, so you’ll need a tool like Selenium WebDriver. Selenium allows you to automate a browser, enabling it to fully render JavaScript-based pages. Use headless browsers such as Chrome or Firefox for efficiency, and set explicit waits to ensure all elements load before scraping.
To avoid overwhelming Zoopla's servers, implement rate limiting by adding 2–5 second delays between requests. Randomizing these delays makes your activity less predictable, reducing the risk of detection.
It’s also wise to include retry logic for failed requests. Network timeouts or temporary server errors can disrupt your scraping process. Use exponential backoff strategies to retry failed requests, ensuring your scraper can recover from minor issues without losing progress.
Error handling is another crucial component. Wrap your scraping code in try-except blocks to catch and log errors, such as missing data fields or unexpected changes in HTML structure. This will help you debug and adjust your scraper as needed.
For large datasets, consider implementing checkpointing. Save progress periodically by storing successfully scraped URLs in a separate file. This way, if your script crashes or needs to be restarted, you can pick up where you left off.
Finally, ensure your scraping practices comply with legal and ethical guidelines. Following this step-by-step approach will set you up for efficient and responsible data extraction.
sbb-itb-65bdb53
Legal and Compliance Considerations
Before scraping property listings from Zoopla, it's crucial to carefully review their legal guidelines. Zoopla's Terms of Use clearly state that text and data mining on their platform is prohibited. This serves as a key legal boundary for any data extraction efforts.
It's essential to respect these rules to stay aligned with Zoopla's policies. Following these guidelines not only helps you avoid legal complications but also allows you to explore managed scraping solutions, such as those provided by Web Scraping HQ, within a compliant framework.
Managed Zoopla Scraping with Web Scraping HQ
Web Scraping HQ provides a seamless way to extract real estate data from Zoopla while staying compliant with legal requirements. Given the complexities of Zoopla's Terms of Service, many businesses are turning to managed scraping solutions like Web Scraping HQ to ensure they can access the data they need without running into legal or technical roadblocks. Below, we’ll explore the platform’s features and pricing plans to show how it simplifies Zoopla data scraping.
Features and Benefits of Web Scraping HQ
Web Scraping HQ takes the hassle out of data collection by ensuring accuracy and reliability. Their dual-stage quality assurance (QA) system checks both the structure and content of the data before it’s delivered, eliminating the risk of errors or incomplete datasets - common issues with DIY scraping.
Another standout feature is the inclusion of expert consultation. Their team of data specialists is available to help you fine-tune data schemas and extraction parameters to meet your specific needs. Whether you’re tracking rental trends, monitoring property availability, or analyzing market dynamics, their expertise ensures you’re getting the most out of the data.
Conclusion
Scraping Zoopla property listings requires a careful mix of technical expertise and adherence to legal guidelines. To succeed, you need a well-thought-out plan - starting with clearly defining your data needs and understanding Zoopla's intricate data structure before diving into coding.
Using managed services allows teams to focus on analyzing data rather than dealing with infrastructure or compliance headaches. Partnering with a service like Web Scraping HQ not only ensures legal compliance but also streamlines the entire data collection process, giving organizations a competitive edge by enabling them to concentrate on valuable, data-driven insights.
Want this done for you?
Send us the URLs. We'll quote it in 24 hours.
Paste the URL(s) you want scraped. We'll reply within 24 hours with a feasibility check and a ballpark quote.


