Jump to section
- Understanding Etsy's Website Structure
- Key Page Types for Scraping
- Setting Up Your Scraping Environment
- Environment Setup
- Building an Etsy Scraper with Python
- Installing Dependencies
- Extracting Data from Etsy Pages
- Handling Pagination and Dynamic Content
- Exporting Data
- Using Web Scraping HQ for Managed Etsy Data Extraction
- Pricing Plans Tailored to Your Needs
- Legal and Ethical Considerations
- Conclusion
How to Scrape Etsy Data?
Scraping Etsy data can help businesses and researchers access public information like product listings, seller details, pricing, and customer reviews. This data is often used for market research, pricing strategies, and competitor analysis. However, scraping Etsy comes with challenges like dynamic content, JavaScript reliance, and legal considerations.
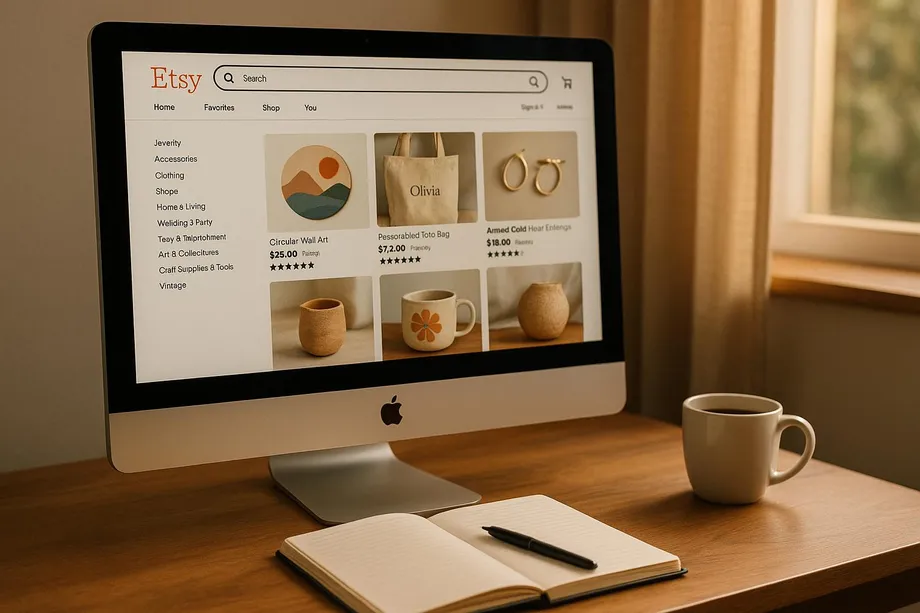
Understanding Etsy's Website Structure
Etsy organizes its website into distinct page types, each tailored to serve specific business and analytical needs. These pages provide targeted data that can be invaluable for market research, competitive analysis, and trend identification.
Key Page Types for Scraping
Etsy's structure revolves around several core page types, each offering unique insights depending on your objectives. Let's break them down:
- Product Detail Pages: These pages are the heart of Etsy's catalog, showcasing individual items. They include essential details like titles, descriptions, prices, available variations (e.g., size and color), shipping costs, customer reviews, and seller information such as shop names, sales numbers, and locations. This data is perfect for analyzing pricing strategies, customer preferences, and SEO opportunities.
- Shop Pages: These provide a comprehensive look at individual sellers, including their entire product catalog, store policies, and overall ratings. They’re a goldmine for competitor analysis and identifying successful sellers within specific niches.
- Search Result Pages: These pages aggregate products based on specific queries, offering insights into trending items, keyword performance, and market saturation. They’re ideal for spotting trends and assessing demand.
- Category Pages: Organized according to Etsy’s hierarchy, these pages help you explore market segments, featured products, and subcategories. They’re useful for discovering niches and analyzing market dynamics.
Setting Up Your Scraping Environment
To effectively scrape Etsy data, you need a well-prepared development environment.
Environment Setup
First, download and install Python 3.x from python.org. After installation, confirm it's properly set up by running this command in your terminal or command prompt:
python --version
This will display the installed Python version.
Next, organize your work by creating a dedicated project directory for your Etsy scraper. This keeps all your files in one place and makes managing your project much easier.
With these steps, you’ve laid the groundwork for your Etsy scraper. Now, you’re ready to install the necessary dependencies and configure proxies and headers.
Building an Etsy Scraper with Python
Ready to build your Etsy scraper in Python? This guide will walk you through creating a functional scraper to extract data from Etsy listings.
Installing Dependencies
First, you'll need to install key Python libraries that make web scraping a breeze. These tools work together to help you fetch and parse Etsy's web pages.
| Library | Purpose |
|---|---|
requests |
Simplifies HTTP requests for fetching web content |
beautifulsoup4 |
Turns HTML into a structured object for easy data extraction |
lxml |
Speeds up parsing and supports XPath and CSS selectors |
soupsieve |
Enhances BeautifulSoup with CSS selector capabilities |
To install these libraries, open your terminal and run:
pip3 install beautifulsoup4 requests soupsieve lxml
Once installed, create a new Python file and import the necessary modules:
import requests
from bs4 import BeautifulSoup
import json
import csv
import time
Now you're ready to start scraping Etsy pages.
Extracting Data from Etsy Pages
The first step in scraping Etsy is fetching the HTML content of a page. Use the requests library to handle HTTP requests and add headers so your scraper mimics a regular browser visit:
def fetch_etsy_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.content
else:
print(f"Failed to fetch page: {response.status_code}")
return None
Once you've fetched the page, use BeautifulSoup to parse the HTML and extract specific data like product titles, prices, and seller names:
def parse_listing_data(html_content):
soup = BeautifulSoup(html_content, 'lxml')
# Extract product title
title_element = soup.find('h1', {'data-test-id': 'listing-page-title'})
title = title_element.text.strip() if title_element else 'N/A'
# Extract price
price_element = soup.find('p', class_='currency-value')
price = price_element.text.strip() if price_element else 'N/A'
# Extract seller name
seller_element = soup.find('span', class_='shop2-review-review-name')
seller = seller_element.text.strip() if seller_element else 'N/A'
return {
'title': title,
'price': price,
'seller': seller
}
This function uses BeautifulSoup with the lxml parser to quickly and efficiently extract the data you need.
Handling Pagination and Dynamic Content
Etsy's listings are often spread across multiple pages. To gather comprehensive data, your scraper needs to handle pagination. Here's how to scrape multiple pages:
def scrape_multiple_pages(base_url, max_pages=5):
all_data = []
for page in range(1, max_pages + 1):
# Construct URL for each page
page_url = f"{base_url}&page={page}"
html_content = fetch_etsy_page(page_url)
if html_content:
soup = BeautifulSoup(html_content, 'lxml')
# Find all listing links on the page
listing_links = soup.find_all('a', {'data-test-id': 'listing-link'})
for link in listing_links:
listing_url = 'https://www.etsy.com' + link.get('href')
listing_html = fetch_etsy_page(listing_url)
if listing_html:
listing_data = parse_listing_data(listing_html)
all_data.append(listing_data)
# Add delay to avoid overwhelming the server
time.sleep(2)
# Delay between pages
time.sleep(3)
return all_data
Etsy pages often load additional content dynamically. While BeautifulSoup works well for static HTML, dynamic content may require identifying AJAX endpoints and sending targeted requests to those URLs.
Exporting Data
Once you've scraped the data, you'll want to save it for further analysis. You can export it to a CSV file for spreadsheets or a JSON file for programmatic use:
def export_to_csv(data, filename='etsy_data.csv'):
if not data:
print("No data to export")
return
with open(filename, 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = data[0].keys()
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for row in data:
writer.writerow(row)
print(f"Data exported to {filename}")
def export_to_json(data, filename='etsy_data.json'):
with open(filename, 'w', encoding='utf-8') as jsonfile:
json.dump(data, jsonfile, indent=2, ensure_ascii=False)
print(f"Data exported to {filename}")
Finally, bring it all together with an example:
# Example usage
search_url = "https://www.etsy.com/search?q=handmade+jewelry"
scraped_data = scrape_multiple_pages(search_url, max_pages=3)
# Export the data
export_to_csv(scraped_data)
export_to_json(scraped_data)
This setup gives you a solid foundation for scraping Etsy. With Python's requests and BeautifulSoup libraries, you can efficiently extract and process data for your specific needs.
sbb-itb-65bdb53
Using Web Scraping HQ for Managed Etsy Data Extraction
Creating your own Etsy scraper in Python can give you complete control, but it’s not always the best option for large-scale data extraction. That’s where Web Scraping HQ steps in. This managed service takes care of the technical headaches - like debugging and avoiding IP blocks - while ensuring your data is accurate, reliable, and compliant with Etsy’s rules.
Web Scraping HQ focuses on product data extraction, delivering structured and ready-to-use datasets from platforms like Etsy. If you’re looking for a hassle-free way to get the data you need, this service has you covered. Let’s break down what makes it such an effective solution.
Pricing Plans Tailored to Your Needs
For businesses that need regular Etsy data updates without heavy customization, the Standard plan ($449/month) is a great fit. It includes structured data delivery, automated quality checks, and expert advice to ensure you’re getting exactly what you need.
If your company has more complex requirements - like custom data formats, faster turnaround times, or seamless integration - the Custom plan (starting at $999/month) is the way to go. This option offers enterprise-level support, priority delivery, and the flexibility to meet mission-critical demands.
Whether you’re just starting to explore Etsy data or you’re already using analytics to drive decisions, Web Scraping HQ makes it easy to get clean, structured data without the hassle of building and maintaining your own scraper. It’s a straightforward, scalable solution for businesses ready to focus on insights rather than infrastructure.
Legal and Ethical Considerations
Following legal and ethical standards is critical to maintaining a trustworthy Etsy data extraction process. Start by reviewing Etsy's Terms of Service to understand any restrictions on data collection. This step lays the groundwork for a responsible and compliant approach to scraping.
A key part of ethical scraping is respecting the site's robots.txt directives. These guidelines help ensure that your activities align with the platform's preferences. Additionally, implement rate limiting to simulate normal browsing behavior, which helps avoid overwhelming Etsy's servers.
It's also important to recognize the legal frameworks that may apply to your activities. For example, U.S. laws like the Computer Fraud and Abuse Act (CFAA) prohibit unauthorized access or bypassing technical safeguards. If your data collection involves personal information, make sure to comply with privacy regulations such as the General Data Protection Regulation (GDPR), the California Consumer Privacy Act (CCPA), or other relevant local laws.
Ethical considerations go beyond merely following the law. Transparency is key - use a descriptive User-Agent string to identify your tools clearly. Handle personal data with care, applying strict security measures to protect it. Collect only the data you truly need and store it securely. This measured approach respects user privacy and helps maintain the integrity of the platform.
Since legal standards can change over time, it's wise to consult with legal professionals to ensure your methods remain both compliant and responsible.
Conclusion
Successfully scraping Etsy data requires both technical skill and a strong sense of ethical responsibility. This guide walks you through the essential steps for creating an Etsy scraper in Python, from navigating the platform's dynamic structure to designing reliable data extraction techniques.
For businesses that need scalable Etsy data extraction, Web Scraping HQ offers managed services starting at $449 per month. They also provide custom solutions for enterprise needs, offering a practical alternative to building and maintaining an in-house scraper.
Whether you choose to build a custom Python scraper or use a managed service, combining technical expertise with a commitment to ethical practices ensures that your data extraction efforts remain reliable, compliant, and valuable. By doing so, you can unlock meaningful insights while respecting legal and industry standards.
Want this done for you?
Send us the URLs. We'll quote it in 24 hours.
Paste the URL(s) you want scraped. We'll reply within 24 hours with a feasibility check and a ballpark quote.


