Jump to section
- Key Points:
- How a Crunchyroll Scraper Works
- What is a Crunchyroll Scraper?
- Main Features of a Crunchyroll Scraper
- Tools and Technologies for Building a Crunchyroll Scraper
- How to Build and Use a Crunchyroll Scraper
- Setting Up Your Environment
- Finding Target Data on Crunchyroll
- Writing the Scraper Code
- Saving the Scraped Data
- Best Practices for Scraping Crunchyroll Data
- Avoiding Detection and Blocks
- Ensuring Data Quality
- Following Legal Requirements
- Conclusion
- Key Takeaways
- Next Steps
How to Scrape crunchyroll Website data?
Scraping data from Crunchyroll involves using automated tools to extract information such as anime titles, genres, release dates, and more. This process can save time compared to manual data collection and is often used for research, analytics, or building recommendation systems. However, it’s essential to follow legal and ethical guidelines, such as respecting the site's robots.txt file and avoiding overloading servers.
Key Points:
- What You Can Extract: Titles, genres, episode details, ratings, reviews, and regional availability.
- Tools to Use: Python libraries like Playwright, BeautifulSoup, or Scrapy; other options include Puppeteer for JavaScript-heavy content.
-
Steps:
- Set up your development environment.
- Identify target data using browser developer tools.
- Write a scraper to fetch and store data in formats like JSON or CSV.
- Best Practices: Use proxies, randomize requests, and add delays to avoid detection. Always comply with Crunchyroll's terms of service and data privacy laws.
Scraping Crunchyroll data can provide valuable insights, but ensure you're staying within legal boundaries and respecting the platform's policies.
How a Crunchyroll Scraper Works
What is a Crunchyroll Scraper?
A Crunchyroll scraper is a tool designed to automate the process of collecting data from Crunchyroll's platform and organizing it into structured formats like JSON, CSV, or databases. This eliminates the need for manually copying details about anime shows and episodes. It can gather a wide range of information, such as anime titles, genres, release dates, cast members, directors, and episode durations. Additionally, it tracks engagement metrics like viewer ratings, reviews, and comments.
Some advanced scrapers can process up to 3.8 million metadata points per hour with an impressive 98.1% accuracy rate. These tools are equipped to handle complex data, including multiple seasons, episode lists, regional content availability, and subtitle URLs. Many scrapers are configured to run on schedules, such as every 30 minutes, to detect new episodes or updates to the catalog automatically. This kind of automation forms the backbone of many powerful data extraction processes.
Main Features of a Crunchyroll Scraper
A well-designed Crunchyroll scraper focuses on extracting specific, targeted data efficiently. For example, it can filter anime based on genres, regions (like the USA, UK, or Japan), or release dates. Real-time monitoring ensures the scraper stays in sync with Crunchyroll's frequent updates, achieving up to 6.7x faster daily synchronization.
Automation is another key feature, allowing the scraper to operate without manual input and send notifications when new shows, seasons, or episodes are added. Export options are also highly flexible. You can save the extracted data as JSON files for hierarchical structures (like series, seasons, and episodes), CSV files for simpler lists, or even directly into SQL databases like SQLite.
Tools and Technologies for Building a Crunchyroll Scraper
Building an efficient Crunchyroll scraper requires the right mix of programming languages and tools. Python is a popular choice, often paired with libraries like BeautifulSoup, Scrapy, Selenium, or Playwright. For handling Crunchyroll's dynamic, JavaScript-rendered content, headless browsers are essential. JavaScript developers might opt for Puppeteer with Node.js, while others may use C# and .NET frameworks. Data can be stored in formats like SQLite, JSON, or CSV.
For working with DRM-protected content or high-quality streams, tools like pywidevine and FFmpeg are useful for decryption and media processing. The scraping process typically involves four main steps: sending HTTP requests to Crunchyroll's servers, parsing the HTML into a DOM tree, extracting data using CSS selectors or XPath, and cleaning the raw data before storing it. These tools and methods ensure the scraper operates efficiently while adhering to ethical practices, supporting a well-rounded data collection strategy.
sbb-itb-65bdb53
How to Build and Use a Crunchyroll Scraper
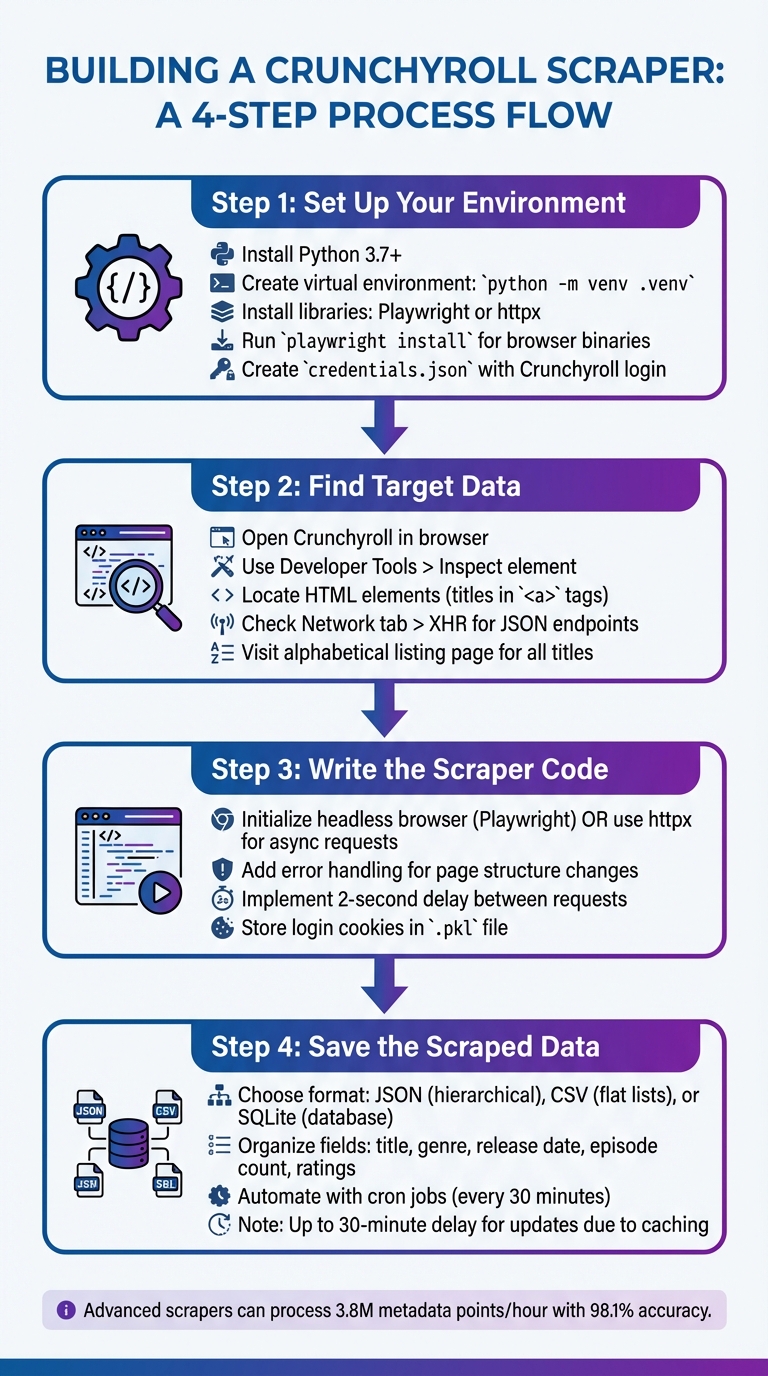
How to Build a Crunchyroll Web Scraper in 4 Steps
Setting Up Your Environment
To get started, you'll need to prepare your development environment. Make sure Python 3.7 or higher is installed and configured in your system's PATH. Create a dedicated project folder, navigate to it in your terminal, and set up a virtual environment by running:
python -m venv .venv
Activate the virtual environment with .venv\Scripts\activate on Windows or source .venv/bin/activate on Unix-based systems. This isolates your project dependencies, preventing conflicts with other Python projects.
Next, install the necessary libraries. Tools like Playwright (great for handling dynamic content) or httpx (for API requests) are essential. If you choose Playwright, run playwright install after installing it with pip to download the required browser binaries. Alternatively, you can use a library like crunpyroll (install via pip install crunpyroll), which simplifies interaction with Crunchyroll's APIs.
Since most scrapers require a valid Crunchyroll account - often a Premium one - to access full metadata and streams, create a credentials.json file in your project folder. This file should securely store your Crunchyroll email and password. Once everything is set up, you’re ready to move on to identifying the data you want to scrape.
Finding Target Data on Crunchyroll
Identifying the specific data you want is crucial for building an effective scraper. Start by opening Crunchyroll in your browser. Use the "Inspect" option (right-click on the page) to open Developer Tools. This will allow you to examine the HTML structure and locate elements like show titles, genres, or episode counts. For example, show titles are often found in <a> tags with a title attribute.
For a simpler approach, visit Crunchyroll’s alphabetical listing page at crunchyroll.com/videos/anime/alpha?group=all. This page conveniently lists all available titles in one place.
If the content loads dynamically as you scroll, switch to the "Network" tab in Developer Tools, filter by "XHR", and look for JSON endpoints (e.g., load.json). These endpoints often contain structured data that can be directly accessed, saving you from parsing complex HTML. However, keep in mind that shows with multiple seasons may require triggering additional "load" events to capture all episode data. By carefully analyzing these elements, you can streamline the scraping process and ensure accurate data extraction.
Writing the Scraper Code
With your environment ready and target data identified, it's time to write the scraper. If you're using Playwright, start by initializing a headless browser instance. This allows you to navigate Crunchyroll pages and extract data from dynamically loaded content. For a more efficient approach, consider using httpx to send asynchronous requests directly to Crunchyroll’s endpoints, bypassing the need to parse raw HTML.
While coding, prioritize robust error handling to deal with unexpected changes in page structure or other issues. Add a 2-second delay between requests to avoid triggering server-side blocks. For authentication, store login cookies in a file (such as .pkl) after the first successful login. This reduces the need to repeatedly log in during subsequent runs. With these practices in place, you'll create a scraper that’s efficient and reliable.
Saving the Scraped Data
Once you've gathered the data, it’s important to store it in a format that suits your needs. JSON works well for hierarchical data like series, seasons, and episodes, while CSV is better for flat lists that can be easily imported into spreadsheets or analysis tools. For more advanced storage, consider using SQLite - a lightweight database that’s easy to query.
Organize your data during the extraction process by creating fields for details like title, genre, release date, episode count, and ratings. If you want your scraper to run regularly - say, every 30 minutes to capture new releases - set up automation using shell scripts or cron jobs on a Linux server. Keep in mind there might be a slight delay (up to 30 minutes) between Crunchyroll updating its site and your scraper detecting the changes due to server-side caching.
Best Practices for Scraping Crunchyroll Data
Once you've established the technical foundation for your Crunchyroll scraper, it's essential to follow best practices to ensure smooth operation and compliance with ethical guidelines.
Avoiding Detection and Blocks
Web platforms today are equipped with advanced systems that can detect and block scrapers almost instantly. As Use-Apify explains, "In 2026, executing concurrent HTTP requests from a singular IP address against a modern web architecture guarantees total operational failure within milliseconds". To avoid this, you’ll need to distribute your requests across multiple IP addresses. Residential proxies are a solid choice, as they use real consumer ISP connections and can achieve up to a 99% success rate.
In addition to proxy rotation, it’s critical to randomize User-Agent strings to avoid detection from repeated, predictable headers. Another key consideration is TLS fingerprinting. Modern Web Application Firewalls analyze the cryptographic handshake to identify non-human traffic. By using tools like curl_cffi, you can replicate a real browser’s TLS stack, making your scraper appear more human-like. Adding random delays of 3–5 seconds and employing exponential backoff (e.g., 1, 2, 4, 8 seconds) can further reduce server strain. If you encounter a 429 error, check the Retry-After header and adjust your scraping frequency accordingly.
| Proxy Type | Detection Risk | Cost | Best Use Case |
|---|---|---|---|
| Datacenter | High (ASN Flagging) | $0.02–$0.30 per IP | For low-security APIs or unprotected endpoints |
| Residential | Low (Real ISP IPs) | Starting at $1.15/GB | Ideal for accessing Crunchyroll libraries and metadata |
| Mobile | Very Low (CGNAT) | $1.15–$30/GB | For high-security targets requiring maximum stealth |
To maintain efficiency and security, your Crunchyroll scraper should combine rotating proxies with dynamic header randomization. This approach ensures consistent data extraction without compromising operational integrity.
Ensuring Data Quality
Once you've addressed detection risks, the focus shifts to maintaining the quality of the data your Crunchyroll scraper collects. Aim for a metadata precision rate of at least 98% by implementing thorough validation protocols. Cross-referencing scraped data with industry benchmarks and OTT media datasets can help identify inconsistencies. Keep in mind that some Crunchyroll tables, like "Popular" lists, may not update frequently, so comparing these with individual series pages can help you catch outdated information.
Crunchyroll often uses XHR/JSON requests to load content dynamically as users scroll. To capture this data, monitor your browser’s developer tools and locate the relevant JSON URLs. Without these, your dataset may end up incomplete. To ensure accuracy, validate fields like title, genre, release date, and language for every record. Seasonal premiere cycles can affect about 24% of catalog listings, so it’s a good idea to run your scraper multiple times daily. Professional services typically synchronize data around 6.7 times per day to maintain real-time accuracy.
Regular updates and validation routines not only improve data accuracy but also ensure that your scraper continues to perform reliably over time.
Following Legal Requirements
Ethical data collection is a non-negotiable aspect of scraping. Your Crunchyroll scraper must comply with regulations like GDPR, CCPA, and LGPD by avoiding the collection of personally identifiable information. Use a transparent User-Agent string that identifies your bot and provides contact details so site administrators can reach out if needed.
"Ethical data collection requires transparency and consent. Content scraping bypasses these principles, as it typically occurs without the website owner's knowledge or permission".
Focus on collecting only the data you need - like titles, genres, and ratings - rather than performing full-page dumps. Schedule large-scale scraping during off-peak hours, such as 3:00 AM local time, to minimize the impact on Crunchyroll’s servers. Ethical scraping prioritizes minimal disruption and transparency in data collection.
Conclusion
Key Takeaways
The rise of the anime streaming industry - growing by 31% year-over-year and reaching a global revenue of $28.4 billion - has made data collection a critical tool for market research and competitive analysis. A well-built Crunchyroll scraper can efficiently gather metadata such as titles, genres, release dates, viewer ratings, and regional availability from a vast catalog of approximately 89,000 series spanning 120 genre classifications.
The technical setup is crucial for success. Since Crunchyroll heavily relies on JavaScript and dynamic content, tools like Playwright or Puppeteer are essential for accurately capturing episode-level metadata. Additionally, the seasonal nature of anime premieres necessitates frequent updates - around 6.7 times daily - to keep data current and relevant.
Ethical considerations are equally important. As Jagdish Mohite, Principal Security Consultant at Akamai, warns:
"Unauthorized data harvesting can lead to lawsuits, fines, and reputational damage."
To avoid such risks, your Crunchyroll scraper must steer clear of collecting personally identifiable information and adhere to regulations like GDPR, CCPA, and LGPD. Scheduling operations during off-peak hours and using rate limiting can help reduce server strain and maintain ethical standards.
By staying compliant and regularly updating your scraper to account for platform changes, you can ensure consistent, reliable data collection. A well-maintained scraper not only simplifies data acquisition but also provides actionable insights, keeping you ahead in a competitive market.
Next Steps
To get started, outline your goals clearly - whether it's tracking content performance, analyzing competitors, or gaining audience insights. Before launching any large-scale scraping operation, review Crunchyroll's Terms of Service and consult legal experts to ensure compliance with platform guidelines and regional laws.
If building and maintaining your own scraper feels overwhelming, consider outsourcing to services like Web Scraping HQ. Their managed solutions handle the complexities of compliant, real-time data collection, freeing you to focus on leveraging insights rather than troubleshooting technical issues when Crunchyroll updates its site.
Want this done for you?
Send us the URLs. We'll quote it in 24 hours.
Paste the URL(s) you want scraped. We'll reply within 24 hours with a feasibility check and a ballpark quote.


